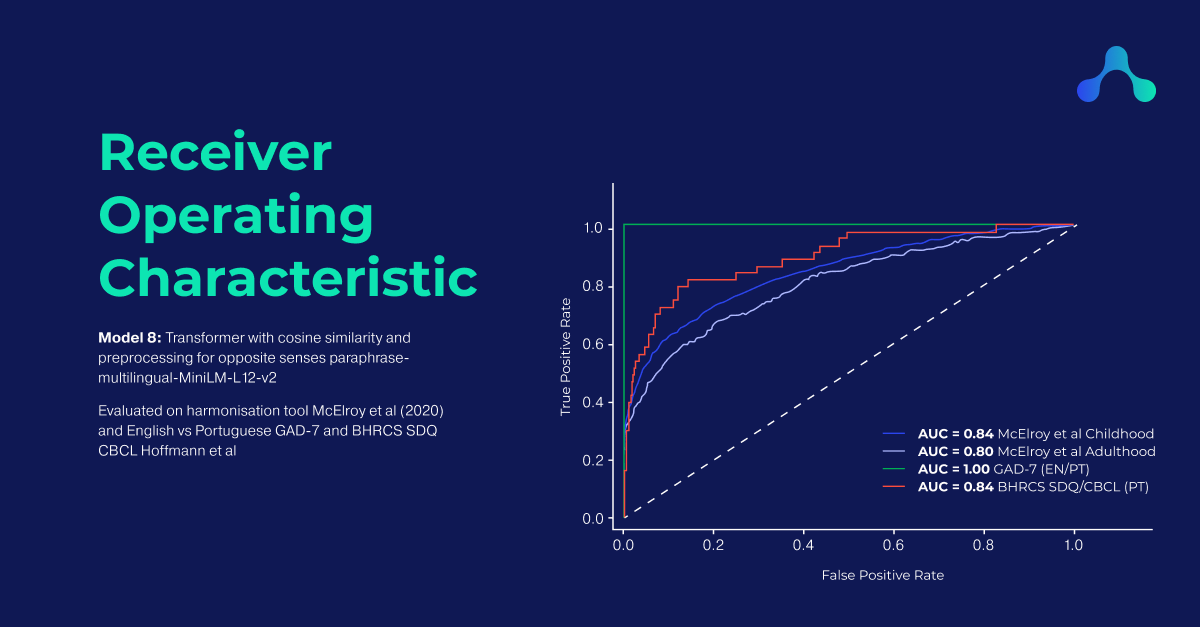
Harmony conseguiu reconstruir as correspondências da ferramenta de harmonização do questionário desenvolvida por McElroy et al em 2020 com as seguintes pontuações AUC: infância 84%, idade adulta 80%. o Harmony foi capaz de igualar as questões dos instrumentos GAD-7 inglês e português com AUC 100% e o CBCL e SDQ português com AUC 89%. o Harmony também foi avaliado usando uma variedade de modelos transformadores, incluindo MentalBERT, um modelo de linguagem pré-treinado publicamente disponível para o domínio da saúde mental.
O conteúdo desta postagem no blog foi escrito como uma pré-impressão para publicação na OSF .
O Harmony é uma ferramenta para comparar questões em linguagem natural de diferentes pesquisas ou instrumentos. Para desenvolver a ferramenta, tivemos que ser capazes de quantificar o quão bom é reconhecer questões equivalentes ou semelhantes. Você pode ler sobre como o Harmony funciona na minha postagem anterior no blog .
Por exemplo, podemos considerar Tenta acabar com brigas é equivalente a É útil se alguém está ferido, chateado ou se sentindo mal, mesmo que não haja palavras em comum entre os dois textos. Mas isso é subjetivo e, se estivermos usando IA para fazer esse tipo de correspondência, como podemos calcular o desempenho de nossa IA?
Estou descrevendo aqui como pude avaliar o Harmony . Você pode visualizar o código dos meus experimentos no Github e experimentar você mesmo.
Eu usei uma ferramenta de harmonização existente desenvolvida por uma equipe da CLOSER ( Harmonização e propriedades de medição de medidas de saúde mental em seis coortes britânicas , McElroy et al, 2020) como padrão-ouro.
Esta ferramenta está disponível como um Excel e mostra uma variedade de instrumentos de diferentes lugares e épocas, e atribui as perguntas dentro deles a um conjunto definido de categorias.

Uma captura de tela da ferramenta de harmonização de McElroy et al (2020). Você pode baixar a ferramenta no formato Excel em nosso repositório Github .
Como o objetivo do Harmony é automatizar, ou pelo menos facilitar, a produção de ferramentas de harmonização como esta, uma maneira fácil de validar a saída do Harmony é fornecer esses dados ao Harmony e verificar se o Harmony produz algo semelhante ao a ferramenta existente.
A ferramenta existente de McElroy et al tem uma seção para questionários de saúde mental de adultos e outra seção para questionários de crianças. Decidi tratar esses dois como conjuntos de dados de validação separados.
Para testar a capacidade multilíngue do Harmony , adicionei também as sete questões do GAD-7 em inglês e português. Se o Harmony conseguiu corresponder corretamente a todas as sete perguntas, isso mostra como o Harmony pode lidar com texto multilíngue.
Por fim, incluí uma ferramenta de harmonização semelhante, apenas em português, listando semelhanças entre o SDQ (Questionário de pontos fortes e dificuldades) e CBCL (A lista de verificação do comportamento infantil) compilado por Hoffmann et al para validar o desempenho monolíngue do português.
O conjunto de dados de validação pode ser dividido da seguinte forma
| Conjunto de dados | Número de instrumentos | Número médio de questões por instrumento |
|---|---|---|
| Infância McElroy e outros | 47 | 23 |
| Idade adulta McElroy et al | 28 | 16 |
| GAD-7 Inglês vs Português | 2 | 7 |
| BHRCS SDQ/CBCL (somente em português) | 2 | 73 |
Detalhamento do meu conjunto de dados de validação
Uma vez que a tarefa do Harmony pode ser vista como uma classificação binária (cada par de perguntas deve ser correspondido ou não), uma métrica para medir o desempenho do Harmony é a curva característica de operação do receptor (ROC) e a área sob a Curva (AUC).
Por exemplo, para o conjunto de dados inglês x português do GAD-7 contém 7 × 7 = 49 possíveis correspondências. 7 deles são positivos (o Q1 no GAD-7 em português é equivalente ao Q1 no inglês), enquanto 42 são negativos (qualquer emparelhamento cruzado de perguntas).
No processo de desenvolvimento do Harmony , não ficou imediatamente claro qual tecnologia deveria ser usada. Antes de tentar a tecnologia de ponta, como redes neurais, era necessário estabelecer uma linha de base para desempenho usando uma ferramenta mais simples, como um modelo de saco de palavras (consulte minha postagem anterior no blog para uma explicação das tecnologias exploradas neste post).
Testei os seguintes modelos candidatos:
Para cada projeto de modelo, gerei uma curva ROC, calculei a AUC e também imprimi alguns exemplos de falsos negativos e falsos positivos.
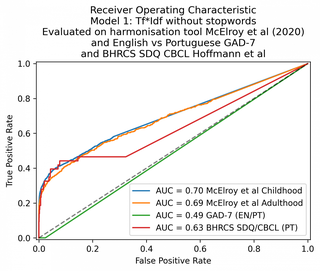
O modelo de linha de base, o Tf*Idf, deu uma AUC de 71% e 67% nos conjuntos de dados da infância e da idade adulta, respectivamente. No inglês x português, obteve uma AUC de 49%, mostrando que não conseguiu realizar nenhuma correspondência. Isso não é surpreendente, pois não há palavras em comum entre os GAD-7s inglês e português.
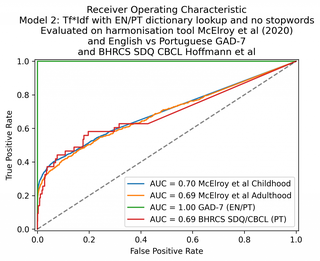
Com uma pesquisa de dicionário codificada manualmente para combinar palavras em inglês e português, o mesmo modelo foi capaz de pontuar 100% no conjunto de dados multilíngue GAD-7. (Arquivo CSV de dicionário disponível aqui ).
O desempenho do modelo Tf*Idf pode ser melhorado por uma pesquisa de dicionário bilíngüe.
A próxima etapa foi tentar uma abordagem de similaridade de vetores de palavras. Usei o spaCy, um dos modelos mais fáceis de usar que permite gerar representações vetoriais de palavras e documentos e compará-los.
No geral, os menores modelos spaCy em inglês e português tiveram desempenho pior do que os modelos Tf*Idf descritos acima. O desempenho do GAD-7 é essencialmente de 50% – o modelo não está realizando nenhuma classificação útil.
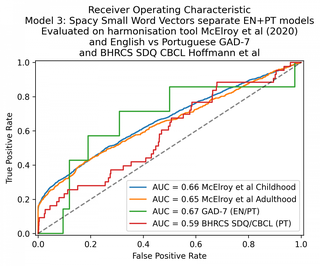
Isso é esperado, pois não esperaríamos que os vetores de palavras em inglês e português fossem equivalentes.
Em seguida, experimentei o modelo spaCy grande, usando a versão em inglês para os dois idiomas. Isso teve um desempenho marginalmente melhor.
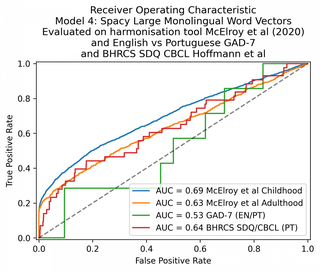
O que há de mais moderno em processamento de linguagem natural são os modelos transformadores. Como as abordagens de vetores de palavras acima, os transformadores convertem sentenças em representações vetoriais, permitindo-nos usar similaridade geométrica e medidas de distância para quantificar a similaridade semântica.
Usei o pacote de software HuggingFace com o modelo Sentence-BERT , que é uma implementação do BERT projetada para gerar incorporações de sentenças semanticamente significativas que podem ser comparadas usando similaridade de cosseno.
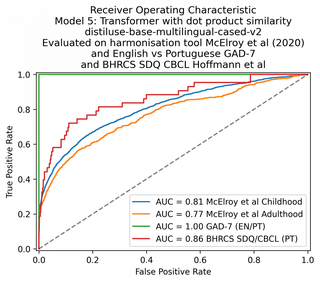
Testei o Sentence-BERT com vários parâmetros de métricas diferentes, alternando entre a similaridade de cosseno e produto de ponto e adicionando uma etapa de pré-processamento manual dependente do idioma para identificar quando duas frases podem ser semelhantes no sentido oposto. Também tentei vários modelos de vetores de documentos diferentes disponíveis no hub HuggingFace.
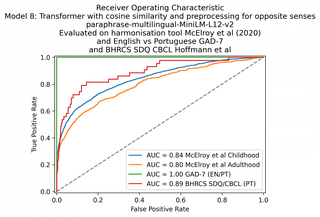
Consegui atingir 84% AUC nos questionários da infância, 80% AUC nos questionários da idade adulta e novamente 100% no GAD-7.
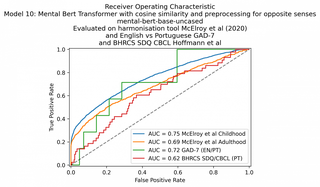
O modelo MentalBERT não teve um desempenho tão bom quanto os outros modelos transformadores de sentenças, apesar de ser específico de domínio. É claro que não esperaríamos que o MentalBERT tivesse um bom desempenho nos dois últimos conjuntos de dados, pois é apenas em inglês e não é multilíngue.
Se você olhar o código para as validações em Github , você pode ver as impressões das questões e como elas foram classificadas. Mostrarei alguns exemplos do meu experimento com o Modelo 7 (transformador Sentença-BERT). O experimento completo e as impressões para o Modelo 7 estão disponíveis aqui .
Por exemplo, o Modelo 7 marcou claramente pares de perguntas equivalentes em português/inglês com valores de similaridade mais altos

Os pares de perguntas marcados como mais semelhantes no conjunto de dados GAD-7 pelo Modelo 7 (transformador)

Os pares de perguntas marcados como menos semelhantes no conjunto de dados GAD-7 pelo Modelo 7 (transformador)
Da mesma forma, aqui está uma impressão dos 10 principais falsos negativos do conjunto de dados Childhood (os pares de perguntas marcados como semelhantes na ferramenta McElroy et al, mas que foram perdidos pelo Harmony ):
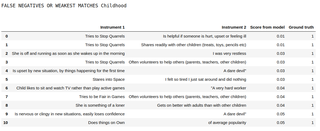
Os 10 principais falsos negativos no conjunto de dados da Infância, classificados pelo Modelo 7 (transformador)
Podemos ver que alguns deles são textos em que o significado é realmente muito diferente, mas em um contexto psicológico gostaríamos de agrupá-los. Por exemplo, está nervoso ou pegajoso em novas situações, perde a confiança facilmente não salta imediatamente para mim como um não psicólogo como algo que agruparíamos com um desafio demoníaco, mas um psicólogo pode querer categorizá-los juntos.
Vamos dar uma olhada nos falsos positivos – estes são pares de perguntas que McElroy et al categorizaram como diferentes, mas o Harmony pensou que eles são semelhantes.

Os 10 principais falsos positivos no conjunto de dados da Infância, classificados pelo Modelo 7 (transformador)
Podemos ver que alguns desses erros de classificação se devem a nuances muito sutis de sintaxe. Para a primeira pergunta acima, a palavra diffident essencialmente nega todo o restante da frase - mas o Harmony classificou as duas frases como muito semelhantes.
Da mesma forma, intimida outras crianças e é intimidado por outras crianças compartilham as mesmas palavras-chave, mas referem-se a questões muito diferentes no contexto do desenvolvimento infantil.
Como poderíamos melhorar o desempenho do Harmony nesses casos? Há uma série de opções:
| Modelo | Criança | Adulto | GAD-7 | CBCL/SDQ |
|---|---|---|---|---|
| 1. Saco-de-palavras | 70 | 69 | 49 | 63 |
| 2. Saco de palavras + pesquisa de dicionário | 70 | 69 | 100 | 69 |
| 3. Pequeno modelo spaCy EN+PT | 66 | 65 | 67 | 59 |
| 4. Modelo de grande espaço | 69 | 63 | 53 | 64 |
| 5. Transformador: distiluse-base-multilingual-case-v2 (semelhança de produto escalar) – pré-processamento sem negação | 81 | 77 | 100 | 86 |
| 6. Transformador: distiluse-base-multilingual-case-v2 (semelhança de produto ponto) | 81 | 77 | 100 | 86 |
| 7. Transformer: distiluse-base-multilingual-case-v2 (semelhança de cosseno) | 81 | 77 | 100 | 86 |
| 8.Transformer: paráfrase-multilíngue-MiniLM-L12-v2 (cosseno) | 84 | 80 | 100 | 89 |
| 9. Transformador: MSTSb_paraphrase-xlm-r-multilingual-v1 (cosseno) | 83 | 75 | 100 | 92 |
| 10. Transformer: mental-bert-uncase (cosseno) | 75 | 69 | 72 | 62 |
Visão geral das pontuações de AUC em porcentagem nos três conjuntos de dados de validação para os modelos que experimentei
O resultado de meus experimentos finais com o Sentence-BERT é reconfortante, pois mostra que um modelo baseado em transformador é capaz de lidar com vários idiomas prontos para uso, sem treinamento ou pré-processamento extra. É emocionante imaginar o potencial do Harmony para abranger ainda mais idiomas. Obviamente, os idiomas em questão devem estar presentes nos dados nos quais o modelo do transformador foi treinado.
Infelizmente, o modelo MentalBERT não teve um desempenho tão bom quanto os outros modelos de transformadores de sentenças, apesar de ser específico do domínio.
É claro que é possível adaptar um algoritmo como a similaridade Tf*Idf para lidar com texto multilíngue com uma pesquisa de dicionário. No entanto, considero a abordagem do transformador mais escalável. A AUC aprimorada usando o Sentence-BERT é uma evidência de que os transformadores superam as alternativas por uma ampla margem. Escrevi outro post de blog sobre as diferentes abordagens para processamento de linguagem natural multilíngue aqui .
Não tentei validar a capacidade do último modelo de reconhecer antônimos. Se você experimentar o Harmony na interface da web , verá que os itens que são previstos como sentidos opostos (criança briga frequentemente vs criança raramente briga) são marcados com linhas vermelhas. Como a ferramenta de harmonização existente não contém essa informação, não consegui validar o reconhecimento de antônimos. Mais trabalho é necessário nesta área.
O trabalho futuro pode envolver o treinamento de um algoritmo de processamento de linguagem natural nas ferramentas de harmonização existentes, a fim de reproduzir seu desempenho. Uma direção futura interessante seria treinar o Harmony para reproduzir os padrões encontrados na análise fatorial, que são derivados de dados de pesquisas numéricas.

