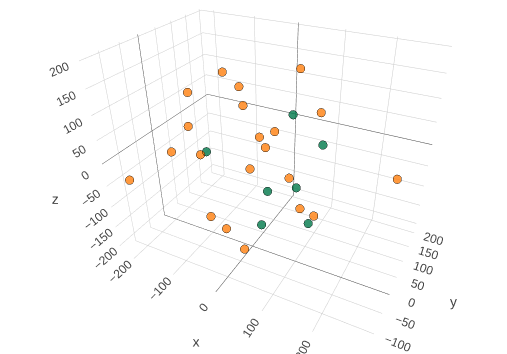
Quando você insere dois questionários no Harmony , como o GAD-7 e o Beck’s Anxiety Inventory , o Harmony é capaz de combinar perguntas semelhantes e atribuir um número à correspondência. (Escrevi outra postagem no blog sobre como medimos o desempenho do Harmony em termos de AUC ).
Então, como o Harmony consegue isso?
O Harmony usa técnicas da área de processamento de linguagem natural para identificar quando duas perguntas tratam de um tópico semelhante. Processamento de linguagem natural, ou NLP, é o campo de estudo sobre as interações entre humanos e computadores por meio da linguagem humana.
Há uma série de abordagens para quantificar a semelhança entre strings de texto. A abordagem mais simples é conhecida como abordagem Bag-of-Words. Não é assim que o Harmony funciona atualmente, mas é uma das primeiras coisas que tentamos!
Se quisermos comparar a pergunta 4 do GAD-7 (Problemas para relaxar) com a pergunta 4 do Inventário de Ansiedade de Beck (Incapaz de relaxar), dividiríamos cada texto nas palavras presentes. Normalmente removemos sufixos como ing neste estágio (isso é chamado de lematização).
| GAD-7 Q4 | Beck Q4 | |
|---|---|---|
| problemas | 1 | 0 |
| relax(ing) | 1 | 1 |
| incapaz | 0 | 1 |
| para | 0 | 1 |
| nervoso | 0 | 0 |
| ansioso | 0 | 0 |
| … | … | … |
No total, existem 4 palavras entre as duas perguntas. Uma palavra (relax) ocorre em ambas as perguntas. Podemos calcular uma métrica de similaridade usando uma fórmula chamada coeficiente de similaridade de Jaccard, que é definido como o número de palavras em ambas as perguntas, dividido pelo número de palavras em qualquer uma das perguntas, portanto, em nosso caso

É fácil ver que o coeficiente de similaridade de Jaccard chegaria a 1 se os documentos fossem idênticos e 0 se os documentos fossem completamente diferentes.
As desvantagens óbvias do método Jaccard são que

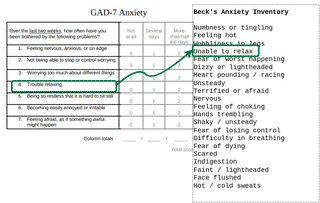
A próxima abordagem que tentamos foi um modelo de espaço vetorial.
Os modelos de espaço vetorial nos permitem representar palavras e conceitos como números ou pontos em um gráfico. Por exemplo, se ansioso pode ser (2, 3), preocupado é (3, 4) e relaxar é (8, 2). As coordenadas de cada conceito não têm sentido, mas se calcularmos a distância entre eles, veremos que ansioso e preocupado estão mais próximos um do outro do que relaxar.
É importante notar que os valores dos vetores são completamente arbitrários. Não há nenhum significado para onde um conceito é atribuído nos eixos x ou y, mas há significado nas distâncias.
Agora temos uma maneira de lidar com sinônimos. Essa abordagem é chamada embeddings de vetores de palavras

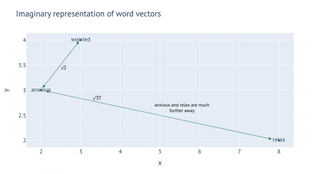
Alguns valores vetoriais de palavras reais para termos que ocorrem em nossos dados. Normalmente, os vetores são grandes, potencialmente até 500 dimensões.
A incorporação de vetores de palavras tornou-se popular em 2013, depois que o cientista da computação tcheco Tomáš Mikolov propôs uma maneira pela qual uma IA pode gerar vetores para cada palavra no idioma inglês simplesmente a partir de um conjunto enorme de documentos.
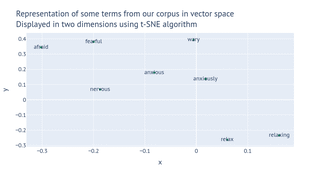
Para visualizar os vetores de palavras, podemos esmagá-los em duas ou três dimensões. Esta é uma visualização 2D dos termos na tabela acima. Usei um algoritmo chamado t-SNE para esmagá-los em uma superfície plana.
Se você quiser experimentar vetores de palavras, visite o site do Nordic Language Processing Laboratory e tente você mesmo.
Se você quiser usar incorporações de vetores de palavras para encontrar sinônimos, poderá calcular o vetor médio de cada pergunta e calcular as distâncias entre os vetores dessa maneira. Isso não vai lidar com coisas como negação (eu não me sinto ansioso), mas é muito mais poderoso do que a abordagem do saco de palavras. Palavras como banco, que tem um significado diferente dependendo do contexto, sempre serão representadas como o mesmo vetor.
Com os dados do Harmony , descobri que os modelos de espaço vetorial não identificaram corretamente a relação entre criança intimida os outros e criança é intimidada pelos outros – que são claramente questões muito diferentes e não devem ser harmonizadas juntas.

Em 2017, uma equipe de pesquisadores do Google publicou um artigo intitulado Atenção é tudo que você precisa , onde propuseram um tipo especial de rede neural chamada rede Transformer, capaz de mover ao longo de uma string de texto e gerar um vetor em cada ponto do documento, levando em consideração o contexto no restante do documento.
A rede neural do transformador usa um mecanismo de atenção, que é um componente que faz com que ela preste atenção extra às palavras da frase que estão fortemente ligadas à palavra que está olhando.
Por exemplo, ao analisar o texto Sentindo medo como se algo horrível pudesse acontecern, um mecanismo de atenção prestaria muita atenção à palavra algo ao analisar a palavra horrível.
Representações vetoriais do GAD-7 e do Inventário de Ansiedade de Beck Calculado usando GPT-2 Reduzido para três dimensões usando t-SNE.
Como um aparte, os transformadores também podem ser usados para tradução automática (na verdade, o Google Tradutor agora usa transformadores), e essa atenção permite que uma frase substantivo+adjetivo seja traduzida para outro idioma com o gênero correto.

A palavra vermelho pode ser traduzida de várias maneiras diferentes para o português, dependendo do gênero e do substantivo a ser modificado. Os modelos de transformadores são hábeis em levar essas pistas ao contexto e produzir a tradução correta de uma frase.
Para o Harmony , estamos usando um modelo de transformador AI de código aberto chamado GPT-2, que foi desenvolvido pela OpenAI em 2019 .
GPT-2 converte o texto de cada pergunta em um vetor em 1600 dimensões.
A distância entre quaisquer duas questões é medida de acordo com a métrica de similaridade de cosseno entre os dois vetores. Duas perguntas com significado semelhante, mesmo que redigidas de maneira diferente ou em idiomas diferentes, terão um alto grau de semelhança entre suas representações vetoriais. Questões muito diferentes tendem a estar distantes no espaço vetorial.

Quando o Harmony recebe dois ou mais questionários, o texto de cada pergunta é comparado a cada pergunta em todos os outros documentos. Por exemplo, a pergunta 1 do GAD-7 seria vetorizada e comparada com todas as perguntas do PHQ-9, mas não com qualquer outra pergunta do GAD-7.
Em seguida, encontramos as correspondências mais próximas e as vinculamos em um gráfico.
Como essa abordagem é potencialmente propensa a erros, fornecemos a facilidade para um usuário editar o gráfico de rede e adicionar e remover arestas se discordar das decisões do Harmony .
O usuário tem a opção de adicionar ou remover arestas do gráfico.
Com o objetivo de tornar nossa pesquisa o mais acessível possível ao público, tornamos o Harmony , seu código-fonte e dados públicos. O código-fonte e os dados-fonte estão no GitHub e são executados em Python. Se você tem algum conhecimento básico de Python, fique à vontade para baixá-lo e pode até contribuir com o projeto, fazendo um branch e enviando um pull request.
As perguntas geralmente vêm com um conjunto de opções como definitivamente não, um pouco ansioso e assim por diante. Geralmente, são uma forma de escala Likert . Gostaríamos de aplicar a mesma lógica para corresponder às respostas do candidato em uma pergunta e identificar quando as perguntas têm polaridade oposta (muitas vezes me sinto ansioso versus raramente me sinto ansioso).
O Harmony foi projetado para processar arquivos de entrada em formato Excel ou PDF. Extrair as perguntas de um PDF é muito difícil devido à enorme variedade de formatos e sistemas de numeração. Gostaríamos de adicionar um melhor suporte para diferentes formatos de PDF.
No momento, o Harmony processa apenas os textos das perguntas, mas não lida com as respostas da pesquisa. Após a harmonização, a calibração dos dados de pesquisa é o próximo passo no processo de consolidação da pesquisa de diferentes fontes. Gostaríamos de adicionar um recurso para processar dados brutos de pesquisa na ferramenta.
Até agora ignoramos a ordem das perguntas em um instrumento. No mundo real, as pessoas respondem de maneira diferente a uma pergunta, dependendo das perguntas anteriores. Pode haver uma oportunidade de modelar esses efeitos no Harmony em um estágio posterior do projeto.

