We are excited to announce that Harmony, an open source Natural Language Processing tool for data harmonisation, is now available on the Comprehensive R Archive Network CRAN!
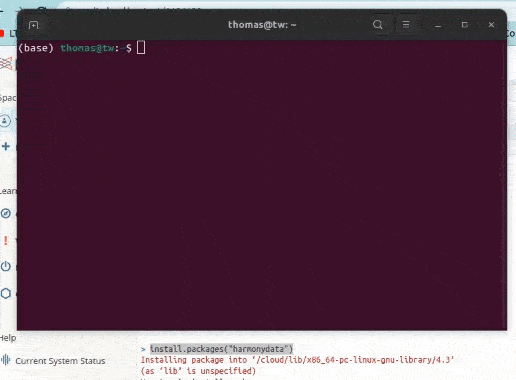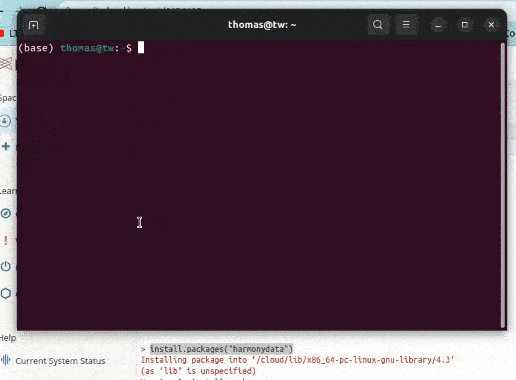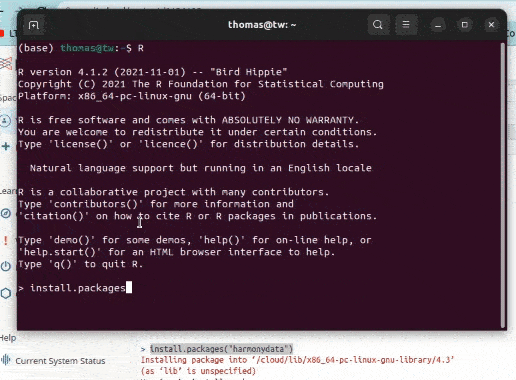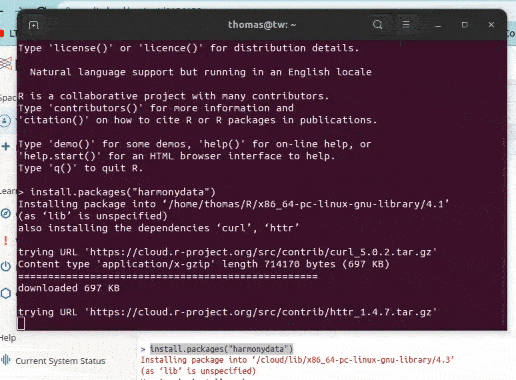
Previously, Harmony R could be installed using devtools.
Harmony can be used to compare questionnaire items across studies, find the best match for a set of items, and identify different versions of the same questionnaire. Harmony is a collaboration project between Ulster University, University College London, the Universidade Federal de Santa Maria, and Fast Data Science. It has been funded by Wellcome as part of the Wellcome Data Prize in Mental Health, as well as UKRI.
To install Harmony, you can use the following command in your R console or R Studio:
install.packages("harmonydata")
We encourage you to try Harmony and let us know what you think! You can also follow us on Twitter @harmonydata for updates.
Here is a quick walkthrough on how to do it:
library(harmonydata)
instrument = load_instruments_from_file(path = "examples/GAD-7.pdf")
instrument_2 = load_instruments_from_file("https://medfam.umontreal.ca/wp-content/uploads/sites/16/GAD-7-fran%C3%A7ais.pdf")
instruments = append(instrument, instrument_2)
match = match_instruments(instruments)
names(match)
#> [1] "questions" "matches" "query_similarity"
As you can see, the match object contains a lot of information about the best match for each question in the query instrument. This information can be used to harmonise the instruments and make them more comparable.
We hope this walkthrough is helpful. Let us know if you have any other questions.
I’m so excited to see what you can do with Harmony!

