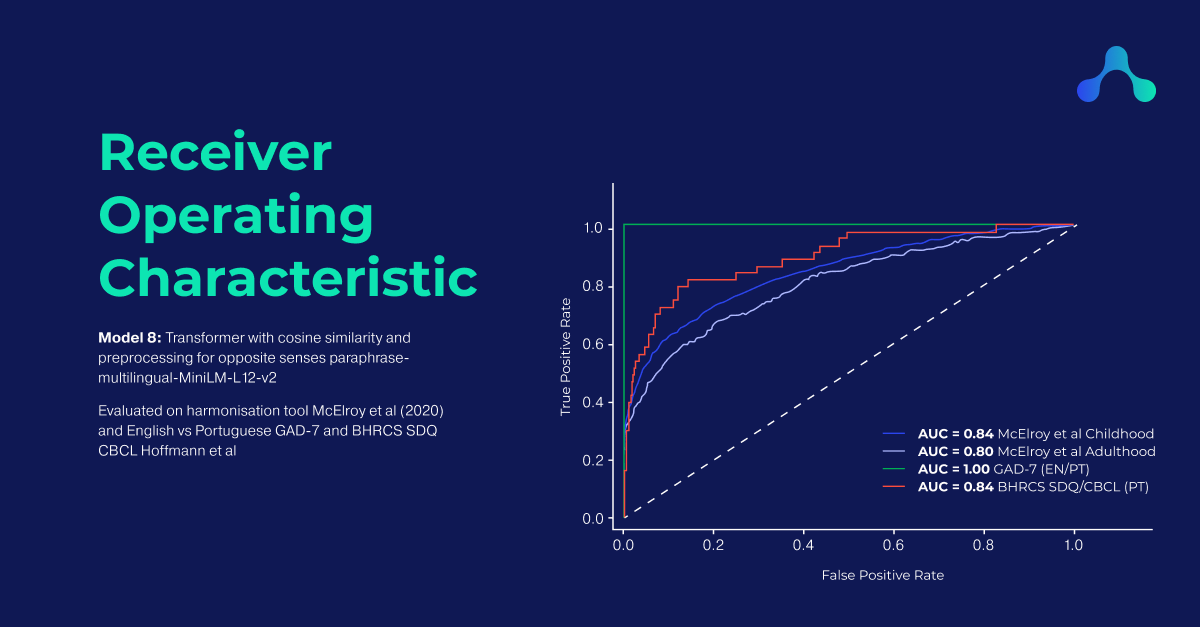
Harmony was able to reconstruct the matches of the questionnaire harmonisation tool developed by McElroy et al in 2020 with the following AUC scores: childhood 84%, adulthood 80%. Harmony was able to match the questions of the English and Portuguese GAD-7 instruments with AUC 100% and the Portuguese CBCL and SDQ with AUC 89%. Harmony was also evaluated using a variety of transformer models including MentalBERT, a publicly available pretrained language model for the mental healthcare domain.
The content of this blog post has been written up as a preprint for publication on OSF.
Harmony is a tool for comparing questions in natural language from different surveys or instruments. In order to develop the tool, we had to be able to quantify how good it is at recognising equivalent or similar questions. You can read about how Harmony works in my earlier blog post.
For example, we might consider Tries to Stop Quarrels is equivalent to Is helpful if someone is hurt, upset or feeling ill, even though there are no words in common between the two texts. But this is subjective, and if we are using AI to make this kind of matches, how can we put a number on our AI’s performance?
I am describing here how I was able to evaluate Harmony. You can view the code of my experiments on Github and try it yourself.
I used an existing harmonisation tool developed by a team at CLOSER (Harmonisation and measurement properties of mental health measures in six British cohorts, McElroy et al, 2020) as a gold standard.
This tool is available as an Excel and shows a variety of instruments from different places and times, and assigns the questions within them to a defined set of categories.

A screenshot of the harmonisation tool by McElroy et al (2020). You can download the tool in Excel format on our Github repository.
Since Harmony’s purpose is to automate, or at least facilitate, the production of harmonisation tools such as this, an easy way to validate Harmony’s output is to give Harmony this data and check that Harmony produces something similar to the existing tool.
The existing tool by McElroy et al has a section for adult mental health questionnaires, and another section for child questionnaires. I decided to treat these two as separate validation datasets.
In order to test Harmony’s multilingual capabilities, I also added the seven questions of the GAD-7 in English and Portuguese. If Harmony was able to correctly match all seven questions, this shows how Harmony can handle multilingual text.
Finally, I included a similar Portuguese-only harmonisation tool listing commonalities between the SDQ (Strengths and Difficulties Questionnaire) and CBCL (The Child Behavior Checklist) compiled by Hoffmann et al to validate the Portuguese monolingual performance.
The validation dataset can be broken down as follows
| Dataset | Number of instruments | Average number of questions per instrument |
|---|---|---|
| Childhood McElroy et al | 47 | 23 |
| Adulthood McElroy et al | 28 | 16 |
| GAD-7 English vs Portuguese | 2 | 7 |
| BHRCS SDQ/CBCL (Portuguese only) | 2 | 73 |
Breakdown of my validation dataset
Since Harmony’s task can be seen as a binary classification (each pair of questions should be matched or should not be matched), one metric to measure Harmony’s performance is the Receiver Operating Characteristic curve (ROC) and the Area Under the Curve (AUC).
For example, for the GAD-7 English vs Portuguese dataset contains 7×7 = 49 potential matches. 7 of these are positives (Q1 in the Portuguese GAD-7 is equivalent to Q1 in the English), while 42 are negatives (any cross-pairing of questions).
In the process of developing Harmony, it was not immediately apparent which technology should be used. Before trying cutting-edge technology such as neural networks, it was necessary to establish a baseline for performance using a simpler tool such as a bag-of-words model (see my earlier blog post for an explanation of the technologies explored in this post).
I tested the following candidate models:
For each model design, I generated a ROC curve, calculated the AUC, and also printed out some examples of false negatives and false positives.
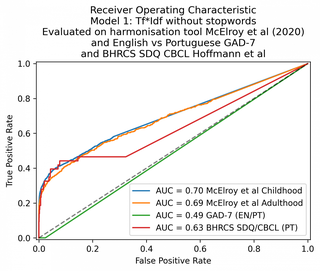
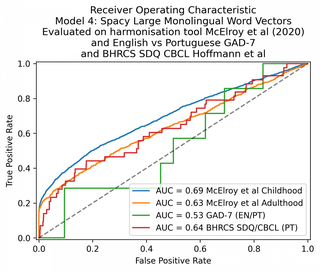
The baseline model, the Tf*Idf, gave a 71% and 67% AUC on the childhood and adulthood datasets respectively. On the English vs Portuguese it scored a 49% AUC, showing that it was unable to perform any matching at all. This is not surprising as there are no words in common between the English and Portuguese GAD-7s.
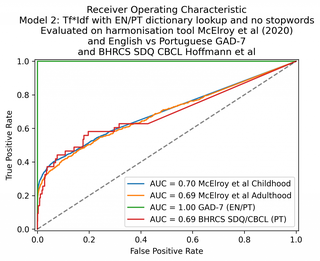
With a hand-coded dictionary lookup to match English and Portuguese words to each other, the same model was able to score 100% on the GAD-7 multilingual dataset. (Dictionary CSV file available here).
The performance of the Tf*Idf model could be improved by a bilingual dictionary lookup.
The next stage was to try a word vector similarity approach. I used spaCy, one of the most user-friendly off-the-shelf models that allows you to generate vector representations of words and documents and compare them.
Overall, the smallest spaCy English and Portuguese models performed worse than the Tf*Idf models described above. The GAD-7 performance is essentially 50% – the model is not performing any useful classification at all.
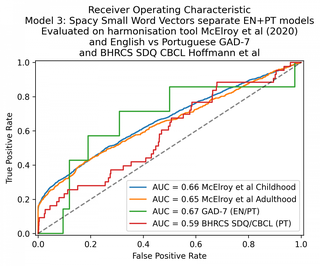
This is to be expected, as we would not expect the English and Portuguese word vectors to be at all equivalent.
I then tried the large spaCy model, using the English version for both languages. This performed marginally better.
The state-of-the-art in natural language processing is currently transformer models. Like the word vector approaches above, transformers convert sentences into vector representations, allowing us to use geometrical similarity and distance measures to quantify semantic similarity.
I used the software package HuggingFace with the multilingual Sentence-BERT model, which is an implementation of BERT that is designed to generate semantically meaningful sentence embeddings which can be compared using cosine similarity.
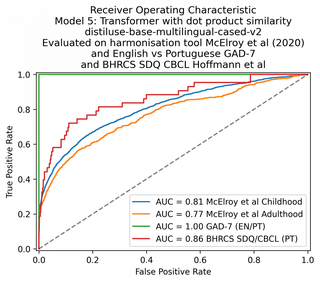
I tested Sentence-BERT with a number of different metrics parameters, switching between Cosine and Dot-product similarity, and adding a manual language-dependent preprocessing step to identify when two sentences may be similar in the opposite sense. I also tried a number of different document vector models available on the HuggingFace hub.
I was able to reach 84% AUC on the childhood questionnaires, 80% AUC on the adulthood questionnaires, and again 100% on the GAD-7.
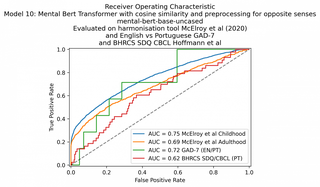
The MentalBERT model did not perform as well as the other sentence transformer models, despite being domain-specific. Of course we would not expect MentalBERT to perform well on the latter two datasets since it is English-only and not multilingual.
If you look at the code for the validations in Github, you can see printouts of the questions and how they were classified. I’ll show a few examples from my experiment with Model 7 (Sentence-BERT transformer). The full experiment and printouts for Model 7 are available here.
For example, Model 7 has clearly tagged equivalent Portuguese/English question pairs with higher similarity values

The question pairs marked as most similar in the GAD-7 dataset by Model 7 (transformer)

The question pairs marked as least similar in the GAD-7 dataset by Model 7 (transformer)
Likewise, here is a printout of the Childhood dataset’s top 10 false negatives (the question pairs that are marked as similar in the McElroy et al tool but which were missed by Harmony):
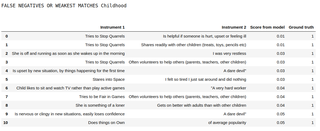
The top 10 false negatives in the Childhood dataset as classified by Model 7 (transformer)
We can see that some of these are texts where the meaning is really very different, but in a psychology context we would want to group them together. For example, is nervous or clingy in new situations, easily loses confidence does not immediately leap out to me as a non-psychologist as something that we would group with a dare devil, but a psychologist may want to categorise them together.
Let’s have a look at the false positives – these are question pairs which McElroy et al categorised as different, but Harmony thought that they are similar.

The top 10 false positives in the Childhood dataset as classified by Model 7 (transformer)
We can see that some of these misclassifications are due to very subtle nuances of syntax. For the first question above, the word diffident essentially negates the entire rest of the sentence – but Harmony has rated the two sentences as very similar.
Likewise, bullies other children and is bullied by other children share the same keywords but refer to very different issues in the context of child development.
How could we improve Harmony’s performance for these cases? There are a number of options:
| Model | Child | Adult | GAD-7 | CBCL/SDQ |
|---|---|---|---|---|
| 1. Bag-of-words | 70 | 69 | 49 | 63 |
| 2. Bag of words + dictionary lookup | 70 | 69 | 100 | 69 |
| 3. Small spaCy model EN+PT | 66 | 65 | 67 | 59 |
| 4. Large spaCy model | 69 | 63 | 53 | 64 |
| 5. Transformer: distiluse-base-multilingual-cased-v2 (dot product similarity) – no negation preprocessing | 81 | 77 | 100 | 86 |
| 6. Transformer: distiluse-base-multilingual-cased-v2 (dot product similarity) | 81 | 77 | 100 | 86 |
| 7. Transformer: distiluse-base-multilingual-cased-v2 (cosine similarity) | 81 | 77 | 100 | 86 |
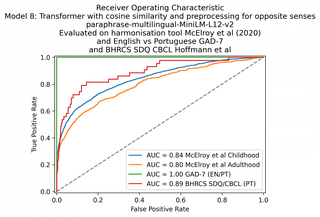
| 8.Transformer: paraphrase-multilingual-MiniLM-L12-v2 (cosine) | 84 | 80 | 100 | 89 |
| 9. Transformer: MSTSb_paraphrase-xlm-r-multilingual-v1 (cosine) | 83 | 75 | 100 | 92 |
| 10. Transformer: mental-bert-uncased (cosine) | 75 | 69 | 72 | 62 |
Overview of AUC scores in percent on the three validation datasets for the models that I experimented with
The outcome of my final experiments with Sentence-BERT is reassuring as it shows that a transformer-based model is able to handle multiple languages out of the box with no extra training or preprocessing. It is exciting to imagine the potential for Harmony to cover even more languages. Of course, the languages in question must have been present in the data that the transformer model was trained on.
Unfortunately the MentalBERT model did not perform as well as the other sentence transformer models, despite being domain-specific.
It is clear that it is possible to adapt an algorithm such as Tf*Idf similarity to handle multi-lingual text with a dictionary lookup. However, I consider the transformer approach to be more scalable. The improved AUC using Sentence-BERT is evidence that transformers outperform the alternatives by a wide margin. I’ve written another blog post about the different approaches to multilingual natural language processing here.
I have not attempted to validate the last model’s ability to recognise antonyms. If you try Harmony in the web interface, you will see that items which are predicted to be opposite senses (child fights frequently vs child rarely fights) are tagged with red lines. Since the existing harmonisation tool does not contain this information, I was unable to validate antonym recognition. Further work is needed in this area.
Future work could involve training a natural language processing algorithm on the existing harmonisation tools, in order to reproduce their performance. An interesting future direction would be to train Harmony to reproduce the patterns found in factor analysis, which are derived from numerical survey data.

