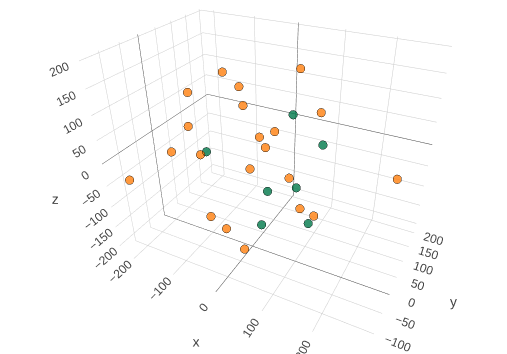
When you input two questionnaires into Harmony, such as the GAD-7 and Beck’s Anxiety Inventory, Harmony is able to match similar questions and assign a number to the match. (I have written another blog post on how we measured Harmony’s performance in terms of AUC).
So how does Harmony achieve this?
Harmony uses techniques from the field of natural language processing to identify when two questions deal with a similar topic. Natural language processing, or NLP, is the field of study concerning interactions between humans and computers via human language.
There are a number of approaches to quantify the similarity between strings of text. The simplest approach is known as the Bag-of-Words approach. This is not how Harmony currently works, but it is one of the first things we tried!
If we want to compare the GAD-7 question 4 (Trouble relaxing) to the Beck’s Anxiety Inventory question 4 (Unable to relax), we would break down each text into the words present. We usually remove suffixes like ing at this stage (this is called lemmatisation).
| GAD-7 Q4 | Beck Q4 | |
|---|---|---|
| trouble | 1 | 0 |
| relax(ing) | 1 | 1 |
| unable | 0 | 1 |
| to | 0 | 1 |
| nervous | 0 | 0 |
| anxious | 0 | 0 |
| … | … | … |
In total there are 4 words between the two questions. One word (relax) occurs in both questions. We can calculate a similarity metric using a formula called the Jaccard similarity coefficient, which is defined as the number of words in both questions, divided by the number of words in either question, so in our case

It is easy to see that the Jaccard similarity coefficient would come to 1 if the documents were identical and 0 if the documents were completely different.
The obvious drawbacks of the Jaccard method are that

The next approach that we tried was a vector space model.
Vector space models allow us to represent words and concepts as numbers or points on a graph. For example, if anxious could be (2, 3), worried is (3, 4) and relax is (8, 2). The coordinates of each concept are themselves meaningless, but if we calculate the distance between them we would see that anxious and worried are closer to each other than either is to relax.
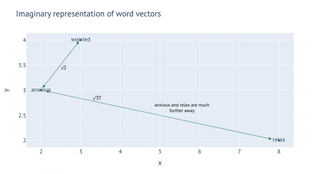
It’s important to note that the values of the vectors are completely arbitrary. There’s no meaning at all to where a concept is assigned on the x or y axes, but there is meaning in the distances.
Now we have a way to handle synonyms. This approach is called word vector embeddings

Some real word vector values for terms occurring in our data. Typically the vectors are large, potentially up to 500 dimensions.
Word vector embeddings became popular in 2013 after the Czech computer scientist Tomáš Mikolov proposed a way that an AI can generate vectors for every word in the English language simply from a huge set of documents.
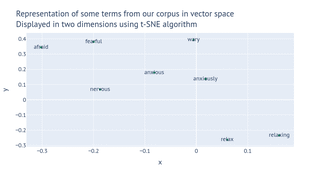
To visualise the word vectors, we can squash them down into two or three dimensions. This is a 2D visualisation of the terms in the table above. I used an algorithm called t-SNE to squash them into a flat surface.
If you would like to experiment with word vectors yourself, you can visit the Nordic Language Processing Laboratory’s website and try it yourself.
If you want to use word vector embeddings to find synonyms, you could calculate the average vector of each question, and calculate the distances between vectors in this way. This will not handle things like negation (I do not feel anxious) but it is much more powerful than the bag-of-words approach. Words such as bank, which has a different meaning depending on context, will always be represented as the same vector.
With the Harmony data, I found that the vector space models did not correctly identify the relationship between child bullies others and child is bullied by others – which are clearly very different questions and should not be harmonised together.

In 2017 a team of researchers at Google published a paper titled Attention Is All You Need, where they proposed a special kind of neural network called a Transformer network which is able to move along a string of text and output a vector at each point in the document, taking into account the context in the rest of the document.
The transformer neural network uses an attention mechanism, which is a component that causes it to pay extra attention to words in the sentence which are strongly linked to the word it’s looking at.
For example, when parsing the text Feeling afraid as if something awful might happen, an attention mechanism would pay strong attention to the word something when parsing the word awful.
Vector representations of the GAD-7 and Beck’s Anxiety InventoryCalculated using GPT-2Collapsed to three dimensions using t-SNE.
As an aside, transformers can also be used for machine translation (in fact Google Translate now uses transformers), and this attention enables a noun+adjective phrase to be translated to another language with the correct gender.

The word red could be translated in various different ways into Portuguese depending on the gender and the noun to be modified. Transformer models are adept at taking these clues into context and outputting the correct translation of a phrase.
For Harmony we are using an open-source AI transformer model called GPT-2, which was developed by OpenAI in 2019.
GPT-2 converts the text of each question into a vector in 1600 dimensions.
The distance between any two questions is measured according to the cosine similarity metric between the two vectors. Two questions which are similar in meaning, even if worded differently or in different languages, will have a high degree of similarity between their vector representations. Questions which are very different tend to be far apart in the vector space.

When Harmony receives two or more questionnaires, the text of each question is compared to each question in every other document. For example, GAD-7 question 1 would be vectorised and compared to all of the questions in the PHQ-9, but not to any other questions in GAD-7.
We then find the closest matches and link them together in a graph.
Because this approach is potentially error-prone, we have provided the facility for a user to edit the network graph and add and remove edges if they disagree with Harmony’s decisions.
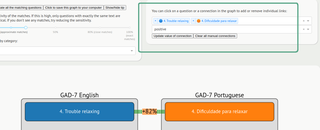
The user has an option to add or remove edges from the graph.
With an aim to make our research as accessible to the public as possible, we have made Harmony and its source code and data public. The source code and source data are on GitHub and runs in Python. If you have some basic knowledge of Python, feel free to download it and you can even contribute to the project, by making a branch and submitting a pull request.
The questions often come with a set of options such as definitely not, somewhat anxious, and the like. These are often a form of Likert scale. We would like to apply the same logic to match the candidate answers in a question, and identify when questions have opposite polarity (I often feel anxious vs I rarely feel anxious).
Harmony is designed to process input files in Excel or PDF format. Extracting the questions from a PDF is fraught with difficulty because of the huge variety of formats and numbering systems. We would like to add better support for different PDF formats.
At present Harmony only processes the question texts but does not handle survey responses. After harmonisation, survey data calibration is the next step in the process of consolidating research from different sources. We would like to add a facility to process raw survey data into the tool.
We have so far ignored the order of the questions in an instrument. In the real world, people respond differently to a question depending on the questions which have come beforehand. There may be an opportunity to model these effects in Harmony at a later stage of the project.

