Harmonisation means taking variables from different studies and manipulating them to make them comparable.
For example, if we have datasets of depression from different countries, which is typically measured using a questionnaire, how can we harmonise two depression questionnaires? Typically this is a manual process – we would look at the content and find common elements between the questionnaires.
For an example of a pre-existing harmonisation tool, please see:
McElroy, E., Villadsen, A., Patalay, P., Goodman, A., Richards, M., Northstone, K., Fearon, P., Tibber, M., Gondek, D., & Ploubidis, G.B. (2020). Harmonisation and Measurement Properties of Mental Health Measures in Six British Cohorts. London, UK: CLOSER.
Harmony is a tool that helps researchers automate the process of harmonisation using natural language processing.
If you would like to cite our validation study, published in BMC Psychiatry, you can cite:
A BibTeX entry for LaTeX users is
@article{mcelroy2024using,
title={Using natural language processing to facilitate the harmonisation of mental health questionnaires: a validation study using real-world data},
author={McElroy, Eoin and Wood, Thomas and Bond, Raymond and Mulvenna, Maurice and Shevlin, Mark and Ploubidis, George B and Hoffmann, Mauricio Scopel and Moltrecht, Bettina},
journal={BMC psychiatry},
volume={24},
number={1},
pages={530},
year={2024},
publisher={Springer}
}
If you would like to cite the Harmony tool alone, you can cite:
Wood, T.A., McElroy, E., Moltrecht, B., Ploubidis, G.B., Scopel Hoffmann, M., Harmony [Computer software], Version 1.0, accessed at https://harmonydata.ac.uk/app. Ulster University (2022)
A BibTeX entry for LaTeX users is
@unpublished{harmony,
AUTHOR = {Wood, T.A., McElroy, E., Moltrecht, B., Ploubidis, G.B., Scopel Hoffman, M.},
TITLE = {Harmony (Computer software), Version 1.0},
YEAR = {2024},
Note = {To appear},
url = {https://harmonydata.ac.uk/app}
}
You can also cite the wider Harmony project which is registered with the Open Science Foundation:
McElroy, E., Moltrecht, B., Scopel Hoffmann, M., Wood, T. A., & Ploubidis, G. (2023, January 6). Harmony – A global platform for contextual harmonisation, translation and cooperation in mental health research. Retrieved from osf.io/bct6k
@misc{McElroy_Moltrecht_Scopel Hoffmann_Wood_Ploubidis_2023,
title={Harmony - A global platform for contextual harmonisation, translation and cooperation in mental health research},
url={osf.io/bct6k},
publisher={OSF},
author={McElroy, Eoin and Moltrecht, Bettina and Scopel Hoffmann, Mauricio and Wood, Thomas A and Ploubidis, George},
year={2023},
month={Jan}
}
There are a number of ways you can help to make this tool better for future users:
If you upload a questionnaire or instrument, Harmony does not store or save it. You can read more on our Privacy Policy page.
Harmony passes the text of each questionnaire item through a neural network called Sentence-BERT, in order to convert it into a vector. The similarity of two texts is then measured as the similarity between their vectors. Two identical texts have a similarity of 100% while two completely different texts have a similarity of 0%. You can read more in this technical blog post and you can even download and run Harmony’s source code.
Harmony was able to reconstruct the matches of the questionnaire harmonisation tool developed by McElroy et al in 2020 with the following AUC scores: childhood 84%, adulthood 80%. Harmony was able to match the questions of the English and Portuguese GAD-7 instruments with AUC 100% and the Portuguese CBCL and SDQ with AUC 89%. You can read more in this blog post and in our validation study in BMC Psychiatry.
The numbers are the cosine similarity of document vectors. The cosine similarity of two vectors can range from -1 to 1 based on the angle between the two vectors being compared. We have converted these to percentages. We have also used a preprocessing stage to convert positive sentences to negative and vice-versa (e.g. I feel anxious → I do not feel anxious). If the match between two sentences improves once this preprocessing has been applied, then the items are assigned a negative similarity.
Harmony reports the cosine similarity score multiplied by +1 or -1 which is our correction for negation. The raw output of Harmony for n questionnaire items is an n × n matrix of similarity scores, with ones along the diagonal. The similarity matrix is also symmetrical about the diagonal since if Item A is 69% similar to Item B, the Item B is naturally 69% similar to Item A.
You are free to choose your own threshold, and we have explored what how a threshold would relate to a correlation in our validation study published in BMC Psychiatry. Some users have reported that a threshold of 0.6 applied to the absolute value of the similarity score from Harmony works well for questionnaire items that are in the same language. Please note that for cross-language matches, Harmony’s similarity score tends to be a little lower, so you may want to explore this and use a lower threshold if you know that your questionnaire items are in different languages.
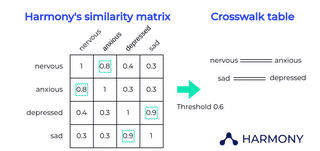
Above: The relationship between the data harmonisation matrix and crosswalk table in Harmony
By default, Harmony uses the HuggingFace model sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2. In the web tool you have the option of switching LLMs to a few other providers including OpenAI.
Above: How to switch LLMs in Harmony’s web UI
Within the Python library, you have the option of choosing any LLM you prefer, including options from Vertex, OpenAI, IBM, HuggingFace, or any of your preferred providers. For example, we have taken the Shona model from the Masakhane project and tested Harmony using a Shona LLM. The README in Github gives some examples of how you can switch the LLM inside Harmony.
At this time Harmony does not give p-values. Harmony matches vectors using a cosine score and p-values are not applicable in this context, since no statistical test is taking place.
Items were matched on content using the online tool Harmony, which matches items by converting text to vectors using a transformer neural network (Reimers & Gurevych, 2019). Harmony produces a cosine score ranging from +/- 1, with values closer to 1 indicating a closer match.
Harmony is based mainly on a large language model but for detecting antonyms, we use a modification that is unique to Harmony. We detect negation words such as “not” and give the cosine match a negative polarity if it looks like sentences are antonyms. This is because LLMs tend to give cosine similarity values roughly between 0 and 1 but tend to give antonyms quite high similarity values, so we wanted to correct for that. There are negation rules for English, French and some other languages in our Github. The negation scripts were the result of the winning entries from our last hackathon.
If you imagine as a human, trying to match items in a questionnaire, you might decide that “I feel depressed” and “I feel sad” are similar. If you had to place them on the surface of a sphere, you might place them close to each other. Whereas different concepts might be far from each other.
We can represent any concept as a vector of length 1, pointing to the surface of a sphere. Concepts that are similar have vectors close together. The cosine score of two vectors that are close together is close to 1.

You can try playing with a large language model in your browser in this blog post. Input two sentences and you can see the vector values and the cosine similarity.
If you want to understand our efforts to calibrate Harmony to human-generated harmonisation scores, please check our validation study.
The Python code of Harmony was written by Thomas Wood (Fast Data Science) in collaboration with Eoin McElroy, Bettina Moltrecht, George Ploubidis, and Mauricio Scopel Hoffman.
The Harmony Python library by default uses topics from the Mental Health Catalogue in the topics_auto field. We are hoping to allow you to configure this to use your own topic modelling.
Harmony does not currently support response categories but this is on our roadmap.
We have developed Harmony as an open-source and open science initiative, paying attention to the FAIR Guiding Principles for scientific data management and stewardship (Findability, Accessibility, Interoperability, and Reuse of digital assets). You can read more on our FAIR data page.
We recently did a user-testing at UCL’s Centre for Longitudinal Studies (CLS) with psychology researchers from several universities. After the session, one postdoctoral researcher said:
