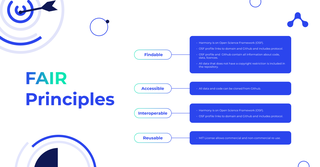
The FAIR principles are a set of guidelines for making data more discoverable, accessible, interoperable, and reusable. The principles are intended to help organizations and individuals maximise the value of their data by making it easier to find, access, and use.
The FAIR principles were published in Nature in 2016 to address the difficulties in reproducing scientific research. Funding organisations, publishers, and governmental agencies are increasingly beginning to require data management plans for data generated in research. This means that if you find a scientific paper and want to reproduce the study, you should be able to reproduce the research with minimal friction.
How is Harmony following FAIR principles?
Harmony’s data is Findable
The Harmony project is registered with the Open Science Foundation. With the exception of copyrighted protocols such as Beck’s Anxiety Inventory, all datasets (protocols) used in the development and testing of Harmony is available on our Github repository which is public access. Datasets not provided in raw form is provided in a shell script which downloads documents from the web. The evaluation set from McElroy et al is provided in the Github repository.
F1. (Meta)data are assigned a globally unique and persistent identifier – The unique identifier for the Harmony project is https://osf.io/bct6k/ with the Open Science Foundation. The OSF profile links to Harmony’s Github page. The Github repository contains a folder of hard coded questionnaires where each questionnaire is in CSV format which serves as the unique ID. For raw PDF questionnaires available on the internet, a shell script is supplied which downloads each data file to an exact filename which serves as a unique identifier.
F2. Data are described with rich metadata – The OSF profile contains all relevant metadata on the project. The spreadsheet Final harmonised item tool EM.xlsx in the repository has a descriptions tab.
F3. Metadata clearly and explicitly include the identifier of the data they describe – the OSF profile links to Github and the Github URL is the unique identifier of the Github repository. All references to a questionnaire refer to the file name in the same format such as GHQ 12 English.
F4. (Meta)data are registered or indexed in a searchable resource – the OSF profile is searchable. In the Github repository, the files are downloaded by the shell script into a folder and there is a script to extract all data into a txt format which is searchable.
Harmony’s data is Accessible
Since our dataset is public access on the Github repository, once a user has cloned (downloaded) the repository and run the shell script, all documents will be on their computer.
A1. (Meta)data are retrievable by their identifier using a standardised communications protocol – Harmony can be downloaded by cloning the Github repository. The script to download any extra questionnaires not supplied with Harmony is included in the Github repository.
A2. Metadata are accessible, even when the data are no longer available – since the unique ID of Harmony is the OSF profile, if Harmony were to be hosted elsewhere the OSF profile would remain with relevant metadata. The list of protocols for testing is included in the shell script. All protocols without open-access restrictions are included in this folder.
Harmony’s data is Interoperable
Data is downloaded in PDF format and the library Apache Tika is used to convert to raw text format. There are no interoperability issues with raw text format.
I1. (Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation. – all questionnaires are converted to a single structure where the text of a question is in one column.
I2. (Meta)data use vocabularies that follow FAIR principles. – You can read the data schema here.
I3. (Meta)data include qualified references to other (meta)data – this item is not applicable since no datasets build on other datasets.
Harmony’s data is Reusable
Harmony is released under the MIT License, which allows commercial use, modification, distribution, and private use of the tool and data.
R1. (Meta)data are richly described with a plurality of accurate and relevant attributes – our project Github page has information about the project, while the source repository has a LICENCE and README.md containing all relevant information about the project and reusability.
References
Wilkinson, Mark D., et al. “The FAIR Guiding Principles for scientific data management and stewardship.” Scientific data 3.1 (2016): 1-9.
Hello! How can I assist you today?
Signup to our newsletter
The latest news on data harmonisation project.
You can unsubscribe at any time by clicking the link in the footer of our emails. For information about our privacy practices, please visit our website. We use Mailchimp as our marketing platform. By clicking below to subscribe, you acknowledge that your information will be transferred to Mailchimp for processing. Learn more about Mailchimp's privacy practices.