
Join a competition to train a Large Language Model for mental health data. You don’t need to have trained a Large Language Model before.
We would like to improve Harmony’s matching algorithm. Sometimes, Harmony mistakenly thinks that sentences are similar when a psychologist would consider them dissimilar, or vice versa. We have evaluated Harmony’s performance in this blog post.
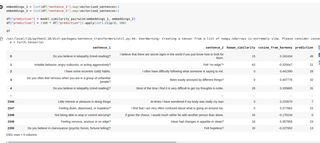
Harmony is sometimes misaligned with human evaluators
We would like to improve Harmony with a fine tuned large language model. We have teamed up with DOXA AI and made an online competition where you can improve on the off-the-shelf LLMs which we are currently using. You can win up to £500 in vouchers! Click here to join the Harmony matching competition on DOXA AI.
We had a livestreamed webinar/onboarding session to launch the competion on Wednesday 30 October at 5pm UK time.
We have gathered training data for you to use to fine tune your model, and there is unseen validation data which we will use to score the model.
More information is available on the DOXA AI page.
First, create an account on DOXA AI and enroll in the competition and download the code examples and training data.
Hugging Face has an excellent guide to fine tuning a large language model. We recommend using Hugging Face because we’ve already designed Harmony around the Hugging Face Python library, and it’s the best known framework for running LLMs in Python.
The prize for the winner of the competition is £500 in vouchers and the runner up will get £250 in vouchers.
The Harmony team has recently published a paper in BMC Psychiatry showing that there is a correlation between Harmony’s cosine similarity values and human evaluators, but this could be improved:
Tutorial on fine tuning your own LLM. Download the notebook used in this tutorial

