
In today’s data-driven world, data harmonisation has become increasingly important. With data coming from disparate sources, it’s essential to ensure that this information is consistent, accurate, and usable. For example, in a large study in social sciences, such as a longitudinal study or meta-analysis, it is common that a researcher may want to combine data from different studies.
We can make data comparable by recoding variables from different studies, modifying them, or identifying which variables in one study match variables in another study. This is data harmonisation.
Data harmonisation involves bringing together data from different sources and transforming it into a unified, coherent format. This process involves standardising disparate data formats, scales, and conventions to make the data compatible and comparable. The goal is to create a dataset where differences in format or scale do not obscure the underlying information.
Data harmonisation makes different sets of data compatible with each other. This process is crucial in data management and analysis, particularly when dealing with large amounts of data from different sources.
There are many cohort and longitudinal studies available in the UK and around the world for researchers to use. However, researchers often need to draw comparisons between studies from different times and places, or studies conducted by different organisations. This may be in order to achieve the necessary sample size for statistical significance, or to determine whether results are consistent across studies or in different conditions.
In social sciences, therefore, data harmonisation is often used by researchers conducting longitudinal or cohort studies, or international studies. It is frequently necessary to harmonise data from several different studies to draw broader conclusions. For example, how studies report topics such as anxiety, household income, or limb function can vary even within professionals within a very narrow and specialised field.
Above: A selection of some of the instruments and questionnaires used in clinical studies. Any meta-analysis combining data that was gathered using different questionnaires would need to involve data harmonisation.
Outside of science and research, data harmonisation is also needed in industry. For example, imagine trying to compare financial reports from different countries, each using its currency and accounting standards. The UK reports industries using the Standard industrial classification of economic activities (SIC) while other countries have their own standards. Without data harmonisation, it is very difficult to combine datasets using disparate schemas.
Data harmonisation enables better decision-making, more accurate analyses, and contributes to the advancement of knowledge and efficiency in multiple domains. Data harmonisation is therefore a critical step in leveraging the full potential of datasets in research and industry.
Psychologists often measure phenomena such as anxiety and depression with instruments, such as the GAD-7 (given below). This would be great if everyone used the same set of instruments, but unfortunately there are over 200 different instruments in use for anxiety.
| No. | GAD-7 English |
|---|---|
| 1 | Feeling nervous, anxious, or on edge |
| 2 | Not being able to stop or control worrying |
| 3 | Worrying too much about different things |
| 4 | Trouble relaxing |
| 5 | Being so restless that it is hard to sit still |
| 6 | Becoming easily annoyed or irritable |
| 7 | Feeling afraid, as if something awful might happen |
| 8 | If you checked any problems, how difficult have they made it for you to do your work, take care of things at home, or get along with other people? |
Where multiple studies have been conducted using different instruments, such as the alternative Beck’s Anxiety Inventory, and a researcher needs to combine data, either to achieve a big enough sample size for the necessary statistical power, or to draw conclusions across populations and timespans (e.g. a longitudinal study), things get a little complicated. For example, there is a manual process of matching question item 4 in the GAD-7 to question item 4 in Beck’s, as illustrated below.

The process of matching items between instruments, studies, or datasets such as GAD-7 and Becks is termed data harmonisation. Data harmonisation has been often done manually in the past in a harmonisation committee. A number of professionals in the field concerned come to an agreement on which items match between studies.
For an example of manual harmonisation by committee, please refer to Harmonisation and measurement properties of mental health measures in six British cohorts by Eoin McElroy et al[1], one of the project leads of Harmony.
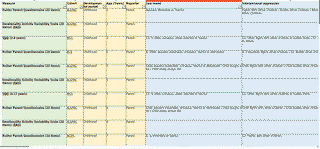
Above: a screenshot from the Excel spreadsheet from McElroy et al[1]
You can find a number of harmonisation efforts and cross-study harmonised datasets from organisations such as CLOSER on the UK Data Service. A data harmonisation workshop with five simulated datasets is also available at GESIS Leibniz Institute for the Social Sciences.
We have developed Harmony (https://harmonydata.ac.uk/app), an AI-driven tool which uses large language models and natural language processing to help researchers with item and data harmonisation. You can try Harmony on the GAD-7 vs Beck’s example with the link below. (You can read this blog post for a technical explanation of how Harmony works.)
Data Discovery, Data Identification and Collection: This step involves identifying the relevant data sources and gathering data from them. It’s crucial to understand the type, format, and structure of the data being collected. This may include data from internal systems, external sources, databases, spreadsheets, or even unstructured data like text files. Harmony Discovery is planned to assist in the data discovery stage.
Data Cleaning and Preprocessing: This involves cleansing the data to ensure its quality. Common tasks include correcting errors, handling missing values, removing duplicates, and addressing outliers. Preprocessing also involves standardizing data, like ensuring consistent naming conventions and formats.
Data Transformation: Here, data is converted into a standardized format or structure. This could involve changing data types, normalizing values (like converting all currencies to a standard currency), standardizing date formats, tabulating the data, or scaling measurements to a common unit. The goal is to ensure that data from different sources can be compared and analysed together.
Data Integration: In this step, the cleaned and transformed data from various sources is merged into a single, unified dataset. This involves aligning data schemas, resolving any conflicts in data structure or content, and ensuring that data from different sources correctly corresponds and aligns with each other.
Quality Assurance: This ongoing process involves continuously monitoring and verifying the quality of the harmonised data. It ensures that the data remains accurate, consistent, and reliable for analysis. Techniques might include data validation checks, periodic reviews, and the use of automated tools to detect and correct data quality issues.
Data Maintenance: Data harmonisation is not a one-time task but an ongoing process. Data maintenance involves regularly updating the dataset with new data, ensuring that changes in source systems are reflected, and continuously managing the quality of the dataset. This step is crucial to ensure that the harmonised data remains current, relevant, and valuable over time.
Each of these steps is critical in the process of transforming diverse and disparate data sources into a cohesive, reliable, and valuable resource for analysis and decision-making. CLOSER has provided a number of guides for data harmonisation as well as some harmonised datasets.
We are currently working on Harmony Discovery, which will extend the functionality of Harmony to allow researchers to discover datasets using semantic matching from large language models. Harmony Discovery is currently connected via API to the following UK-based data catalogues:
*Video of Thomas Wood talking at AI|DL and demoing Harmony
Improved Data Quality: Data harmonisation enhances the accuracy, consistency, and reliability of data. By cleaning and standardizing data, it reduces errors and discrepancies, ensuring that the data is trustworthy and valuable for decision-making. This improved quality is essential for any data-driven process, as it forms the foundation for reliable insights and conclusions.
Better Data Analysis: Harmonised data enables more effective and comprehensive data analysis. Since the data from different sources is brought into a uniform format, it becomes easier to compare, contrast, and analyse. This leads to deeper insights, as data analysts and scientists can work with a cohesive dataset that provides a more complete picture.
Time and Cost Efficiency: Harmonisation automates and streamlines the process of integrating data from various sources, reducing the need for manual data cleaning and adjustments. This efficiency saves significant amounts of time and resources, making data management processes more cost-effective and less labor-intensive.
Enhanced Collaboration: When data is harmonised, it creates a common language and format that can be understood and used across different departments, organizations, or even industries. This facilitates collaboration, as all parties are working with data in a format that is universally recognized and accepted.
Accurate Reporting: Inconsistent and fragmented data can lead to inaccurate reporting and misleading insights. Data harmonisation ensures that reports, analytics, and visualizations accurately reflect the underlying data, leading to more reliable and truthful representations of information.
Regulatory Compliance: Many industries are subject to strict data regulations and standards. Harmonised data is often a requirement for compliance, as it ensures that data is managed, stored, and processed in a way that meets regulatory guidelines. This is particularly important in sectors like healthcare, pharma, finance, and telecommunications.
Enhanced Interoperability: Data harmonisation standardizes data formats, making it easier to share and exchange information across various systems, departments, and organizations. This interoperability is crucial for effective data integration, collaboration, and for leveraging the full potential of digital technologies.
In summary, data harmonisation brings about significant improvements in the quality, usability, and value of data, leading to better decision-making, efficient operations, and compliance with regulatory standards.
Complexity of Data Sources: Data often comes in a myriad of formats and structures from different sources, such as databases, spreadsheets, or even unstructured formats like text files. Harmonising such varied data requires understanding and addressing these complexities, making the process challenging.
Maintaining Data Privacy: Ensuring privacy and security is particularly challenging when dealing with sensitive or personal data. Compliance with data protection regulations (like GDPR) is crucial, and this adds a layer of complexity to the harmonisation process.
Data Governance: Establishing and enforcing clear data governance policies is essential to manage and use data responsibly. This includes setting standards for data quality, access, and usage, which can be complex in organizations with large or diverse data sets.
Resource Intensiveness: Data harmonisation often requires significant resources, including advanced software tools and skilled personnel. The complexity and scale of the task can demand considerable investment in both technology and training.
Data Mapping: Mapping data from various sources involves aligning different data models and structures, which can be particularly challenging. This requires a deep understanding of the semantics and context of the data in each source.
Keeping Up with Changes: Data sources, standards, and technologies are constantly evolving. Keeping the harmonised data up-to-date with these changes requires ongoing effort and adaptability.
Diverse Data Sources: Integrating data from diverse sources adds complexity due to varying formats, standards, and quality. Each source may have its unique characteristics and challenges that need to be addressed in the harmonisation process.
Data Quality Concerns: Ensuring the accuracy, consistency, and reliability of the harmonised data is crucial. This involves identifying and correcting errors in the data, which can be a significant hurdle, especially when dealing with large volumes of data from multiple sources.
Each of these challenges represents a significant aspect of the data harmonisation process, requiring careful planning, skilled resources, and often sophisticated technological solutions to overcome.
Let’s explore this need further in various sectors:
Global Business Operations: For multinational companies, data harmonisation is essential. They deal with data from various countries, each with its regulations, currencies, and operational standards. Without harmonising this data, it becomes challenging to have a unified view of the company’s performance, plan global strategies, or ensure compliance with international regulations.
Healthcare and Medical Research: Patient data from different hospitals, regions, or countries often use different formats and standards. Harmonising this data is vital for epidemiological studies, clinical trials, and public health initiatives. It allows for more accurate analyses, better understanding of diseases, and development of treatments that are effective across diverse populations.
Environmental Studies and Climate Change Research: Environmental data comes from myriad sources: satellite observations, ground-based monitoring stations, and various scientific experiments. To understand global environmental changes and model climate change accurately, this data must be harmonised to ensure consistency and comparability.
Governmental and Public Policy Analysis: Governments need to harmonise data across various departments (such as health, education, and transportation) to make informed policy decisions. Disparate data systems between local, regional, and national levels make it difficult to assess the overall situation and implement effective policies.
Financial Markets and Economic Research: Investors and economists analyse data from different markets and economies. Discrepancies in financial reporting standards, currency values, and economic indicators can lead to misunderstandings and poor decision-making. Harmonised data enables better comparison and understanding of global economic trends.
Technology and Data Science: With the growing field of big data and AI, harmonised data is fundamental for training machine learning models. Diverse data sources must be standardized to ensure that these models are accurate and unbiased.
Supply Chain Management: In global supply chains, harmonising data related to inventory levels, supplier performance, and logistics is crucial for efficiency. Differing data standards across countries and companies can lead to inefficiencies and disruptions.
Education and Comparative Studies: For educational research and international comparisons of educational systems, data harmonisation helps in understanding the effectiveness of different educational approaches and in making cross-country comparisons.
Telecommunications: Telecom companies use data harmonisation to integrate customer data, usage patterns, and network data from various sources. This helps in improving network efficiency, customer service, and in developing new services.
These examples demonstrate the vast applicability and critical importance of data harmonisation in extracting meaningful insights, making informed decisions, and enhancing operational efficiency across different sectors.
Data harmonisation is not a theoretical concept but a practical necessity across various sectors. For instance, in healthcare, harmonising patient data from different hospitals leads to better patient care and research outcomes. In marketing, it helps in understanding consumer behavior by integrating data from diverse sources.
Harmony: A Specialised Tool for Data Harmonisation
Tools like Harmony, designed specifically for the retrospective harmonisation of questionnaire items, are invaluable in research and data analysis. They allow for the comparison and combination of data from different studies or time periods, which is crucial in fields like social sciences, healthcare, and market research.
Perspectives from EPAM and TIBCO Companies like EPAM and TIBCO highlight the strategic importance of data harmonisation. They emphasize how it can provide a competitive edge by ensuring data consistency across an organization, improving decision-making, and streamlining operations.
Future and Role in AI and Machine Learning The future of data harmonisation is closely intertwined with advancements in AI and machine learning. These technologies have the potential to automate the harmonisation process, making it more efficient and accurate. AI can assist in identifying patterns, inconsistencies, and correlations in large datasets, while machine learning algorithms can learn from data to improve the harmonisation process over time, adapting to changes in data structures and formats.
In summary, data harmonisation is a critical and practical process in various industries, enhancing data quality, decision-making, and operational efficiency. The evolution of this field, particularly with the integration of AI and machine learning, holds significant promise for even more streamlined and effective data management in the future.
Data harmonisation is a critical process in today’s data-centric world. It allows organisations to leverage their data more effectively, leading to better decision-making and insights. While the process can be challenging, the benefits of having a unified, high-quality data set are immense. As we continue to generate more and more data, the importance of data harmonisation will only grow, making it an essential skill for data professionals and a critical process for organisations across industries.
Data harmonisation is more than a technical process; it’s a strategic imperative in today’s data-driven world. With tools like Harmony and insights from various resources, organizations can navigate the complexities of data harmonisation to unlock the full potential of their data assets.
Data harmonisation is more than just a technical process; it’s a foundational element for unlocking the full potential of data in any field. By understanding and implementing data harmonisation, we pave the way for a more integrated, insightful, and efficient use of information in our increasingly data-driven world.
McElroy, Eoin, et al. Harmonisation and measurement properties of mental health measures in six British cohorts. UK: CLOSER (2020).
Bechert, Insa, COORDINATE Data Harmonisation Workshop 2, https://doi.org/10.7802/2717
Cheng, C., Messerschmidt, L., Bravo, I. et al. A General Primer for Data Harmonization. Sci Data 11, 152 (2024). https://doi.org/10.1038/s41597-024-02956-3

