Harmony’s research has been published in BMC Psychiatry!
BMC Psychiatry has published our paper validating Harmony on real-world data We are pleased to announce the publication of a paper validating Harmony on real-life data: Using natural language processing to facilitate the harmonisation of mental health questionnaires: a validation study using real-world data, authored by Eoin McElroy, Thomas Wood, Raymond Bond, Maurice Mulvenna, Mark Shevlin, George B. Ploubidis, Mauricio Scopel Hoffmann and Bettina Moltrecht, and published in BMC Psychiatry.
development
Integrating with Harmony
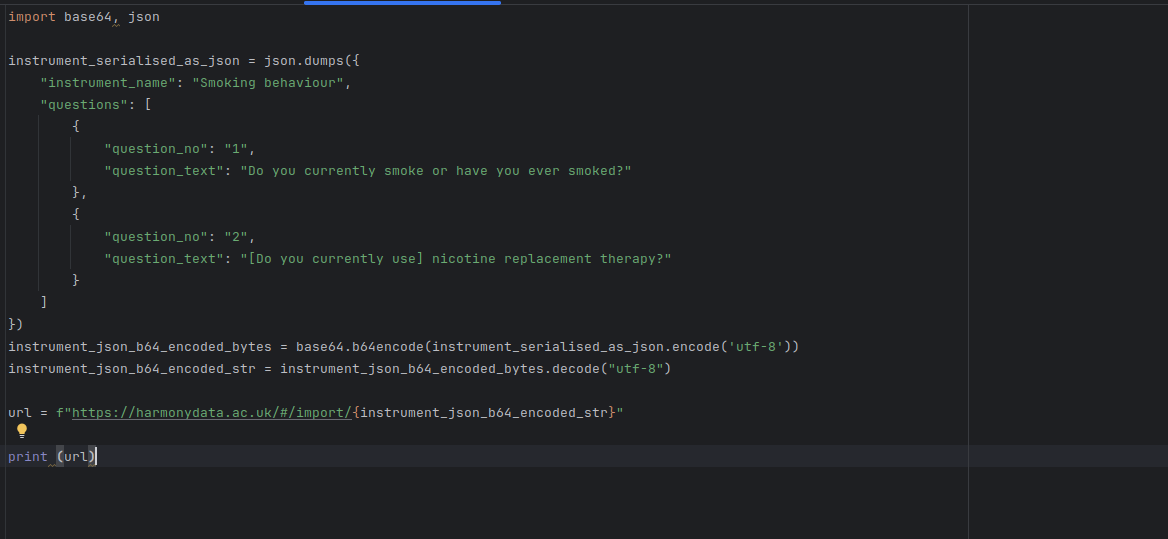
Sending data from another website to Harmony using Javascript We have exposed functionality for external websites to integrate with Harmony and add an “import to Harmony” button, either generated in Javascript or in Python.
Create an Instrument object with at least an instrument_name and questions property in JSON - the questions must have a question_no and question_text properties eg: { "instrument_name": "Smoking behaviour", "questions": [ { "question_no": "1", "question_text": "Do you currently smoke or have you ever smoked?
developmentevents
Pydata on 2 July
Harmony at PyData London - 86th Meetup Update: you can download the slides from the presentation here
Topic: NLP and generative models for psychology research
Thomas Wood will present our work on Harmony, harmonydata.ac.uk, which is a free online tool that uses generative AI and LLMs to help psychologists analyse datasets. It uses Python, Pandas and HuggingFace Sentence Transformers to find similarities between questionnaires.
Psychologists and social scientists often have to match items in different questionnaires, such as “I often feel anxious” and “Feeling nervous, anxious or afraid”.
data
Data Harmonisation in Education
Data Harmonisation in Education: Overview The term ‘harmonisation’ has often been used in different contexts – for example, to describe similar phenomena, such as collaboration, coherence, alignment, integration, partnership, etc. However, we might argue that these concepts might do nothing more than indicate the extent and scale of integration among different entities when it comes to regional cooperation.
Now, the underlying degree of interaction between all the players involved can run a lot deeper and tighter when we transition from collaboration, partnership, and cooperation to integration, community, harmonisation, and interdependence.
data
How To Find Matching and Common Items in Questionnaires and Surveys
When researchers take on the task of analysing data from surveys and questionnaires, they often encounter a significant obstacle: finding matching or common items across different sources. This challenge is due to the many different ways questions are asked or formatted. This makes it tough to compare and merge data effectively.
According to Forbes, researchers spend up to 80% of their time just getting data ready for analysis, and a big part of that time goes into harmonising data.
data
Data Harmonisation in the Public Sector - 6 applications
Overview Public administrations today are tasked with managing massive volumes of data in multiple formats, often using different management methods, as per the demands of their individual organisations. It’s also become common for them to host multiple copies of that data across different repositories.
As a result, the data can often be disseminated across multiple regions, especially in terms of content and presentation, unless it is ‘harmonised’. This is one reason why there is so much re-use at the low level of existing information on citizens and businesses, for example.
data
How to Extract and Process Data from Questionnaires
More than thirty years ago, John Naisbitt put into words a feeling many of us recognise today in “Megatrends,” saying, “We are drowning in information but starved for knowledge.” This statement is incredibly relevant in today’s world, filled to the brim with data for research, analysis, and making decisions. The job of pulling and refining data from questionnaires is key, as these are so many insights and so much valuable feedback.
events
Harmony at Lifecourse seminar
Harmony at Lifecourse seminar On 15 May 2024, Eoin McElroy and Bettina Moltrecht gave a seminar Harmony: A global platform for harmonisation, translation and cooperation in mental health research for the Melbourne Children’s LifeCourse Initiative seminar series.
developmentevents
Harmony Hackathon on 3 June
The Harmony Hackathon Come and join us for a day of coding, collaboration, and creativity at the Harmony Hackathon! Whether you’re a seasoned programmer or just starting out, this event is perfect for anyone interested in tech and innovation. You can sign up on Eventbrite!
The AI Hackathon event will be held at Chandler House (UCL), providing a vibrant and inspiring atmosphere for all participants. Get ready to work on exciting projects, learn new skills, and connect with like-minded individuals.
data
Harmonising Questionnaire Data: 10+1 Practical Steps for Enhanced Consistency
How to Harmonise Questionnaires - 10 Practical Steps (+ 1 Bonus Tip) Data privacy is a big challenge today. It’s all about what we share and what we don’t. Zoher Karu said it well: “One of the biggest challenges is around data privacy and what is shared versus what is not shared. And my perspective on that is consumers are willing to share if there’s value returned. One-way sharing is not going to fly anymore.
Hello! How can I assist you today?
Signup to our newsletter
The latest news on data harmonisation project.
You can unsubscribe at any time by clicking the link in the footer of our emails. For information about our privacy practices, please visit our website. We use Mailchimp as our marketing platform. By clicking below to subscribe, you acknowledge that your information will be transferred to Mailchimp for processing. Learn more about Mailchimp's privacy practices.