Harmony at GenAI and LLMs night at Google London on 10 December 2024 Above: video of the AICamp meetup in London on 10 December 2024. Harmony starts at 40:00 - the first talk is by Connor Leahy of Conjecture
We have presented the AI tool Harmony at the GenAI and LLMs night at Google London on 10th December organised by AI Camp at Google Cloud Startup Hub.
AI Camp and Google hosted two deep dive tech talks on AI, GenAI, LLMs and machine learning, with food/drink, networking with speakers and fellow developers.
ai-in-researchevents
Harmony training workshop
Click to view the video of the training session
Transforming data management with the Harmony Data Tool: A hands-on introduction We’re excited to be partnering with UK Data Service to deliver a practical workshop on how to best use our tools. The session will take place online on 29 November.
With live demonstrations of the Harmony Data Tool’s key functionalities, participants will leave with a clear understanding of how this tool can improve their data management processes which will help improve the efficiency and accuracy of longitudinal data analysis.
development
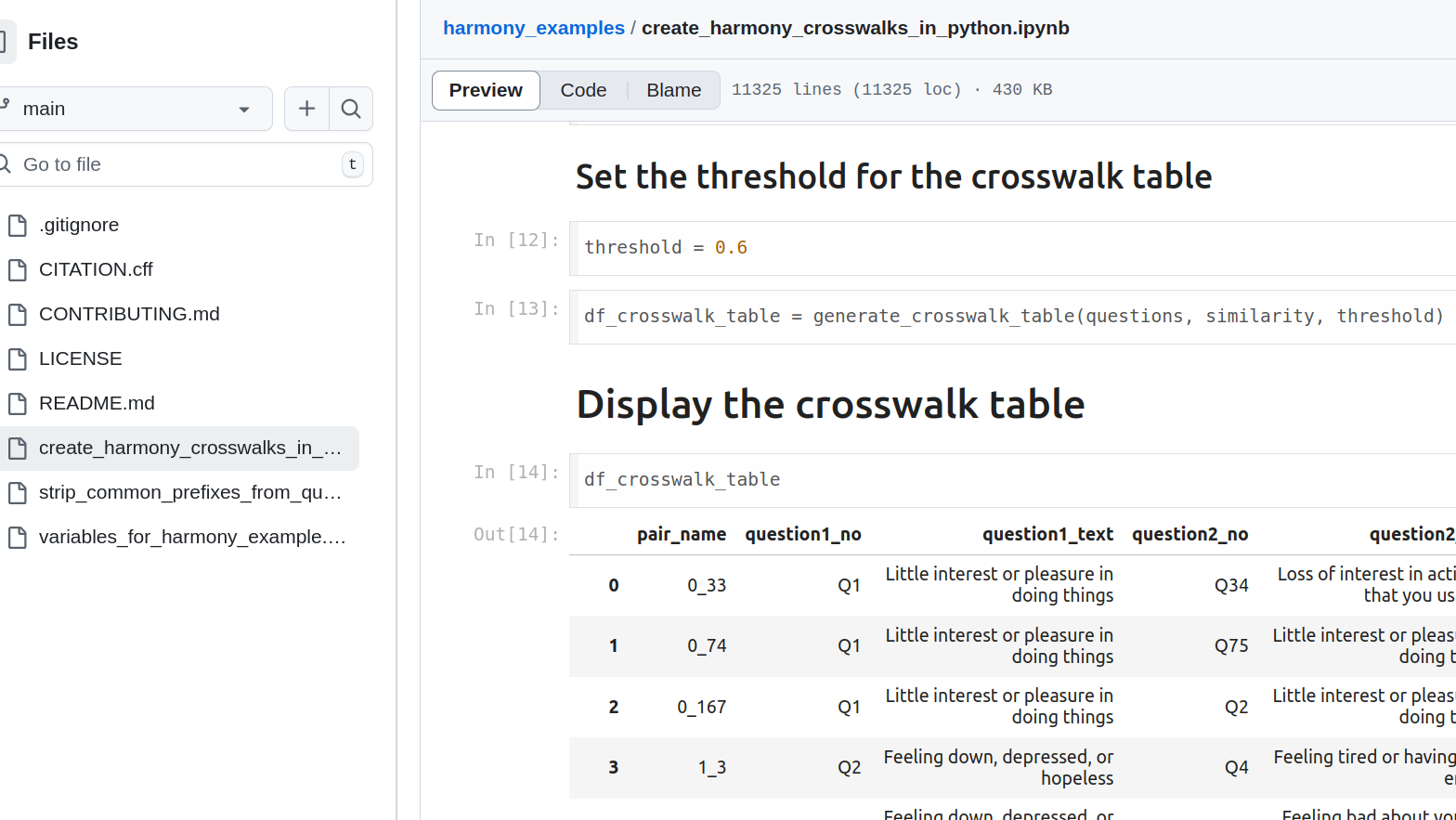
Examples repository: Python and R
For users who have been using Harmony in their research, we have created an example scripts repository here
https://github.com/harmonydata/harmony_examples This contains example R notebooks and Jupyter notebooks. You can upload your own example script if you have something to share with the research community.
Example problems that users have been solving included:
R examples Walkthrough R notebook in R Studio: Walkthrough R notebook in Google Colab: R Markdown to Check for Correspondence between Differently Worded Versions of the Same Scale Item View on Github - credit to Deanna Varley R Script to Check for Matches between Items from Different Scales View on Github - credit to Deanna Varley Python examples Walkthrough Python notebook Example script to create a crosswalk table on real survey data Example script to strip prefixes from questions Documentation View the PDF documentation of the R package on CRAN
development
Harmony Data Discovery
New Feature in Development: Enhancing Harmony with User-Centred Discovery At Harmony, we’re working on a new feature aimed at making data discovery and exploration - through the use of meta-data - even more efficient and intuitive To ensure this feature addresses real needs, we’re conducting co-design sessions with researchers, data-managers and other users, allowing us to develop a tool that solves real-life user requirements.
The Co-Design Approach: Co-design allows us to build this feature with direct input from those who will use it most.
development
Easy issues to get started on in Harmony: Python and R
We have a few more issues that have been added to the issue trackers.
If you are new and would like to make a pull request in either the Python or R libraries feel free to pick these up - they should be quite small.
Easy issues in Python library We would like to expose the “between instrument matches” and the “negation” switches in the Python library and then from the API side.
ai-in-research
Competition to train a Large Language Model for Harmony on DOXA AI
Harmony on DOXA AI: Train your own Large Language Model and win up to £500 in vouchers! Join a competition to train a Large Language Model for mental health data. You don’t need to have trained a Large Language Model before.
Register on DOXA AI Enter the competition on DOXA AI by fine tuning your own large language model and improve Harmony! Join our Discord Join the Harmony Discord server. Check out the 🏅「matching-challenge」 channel!
ai-in-researchevents
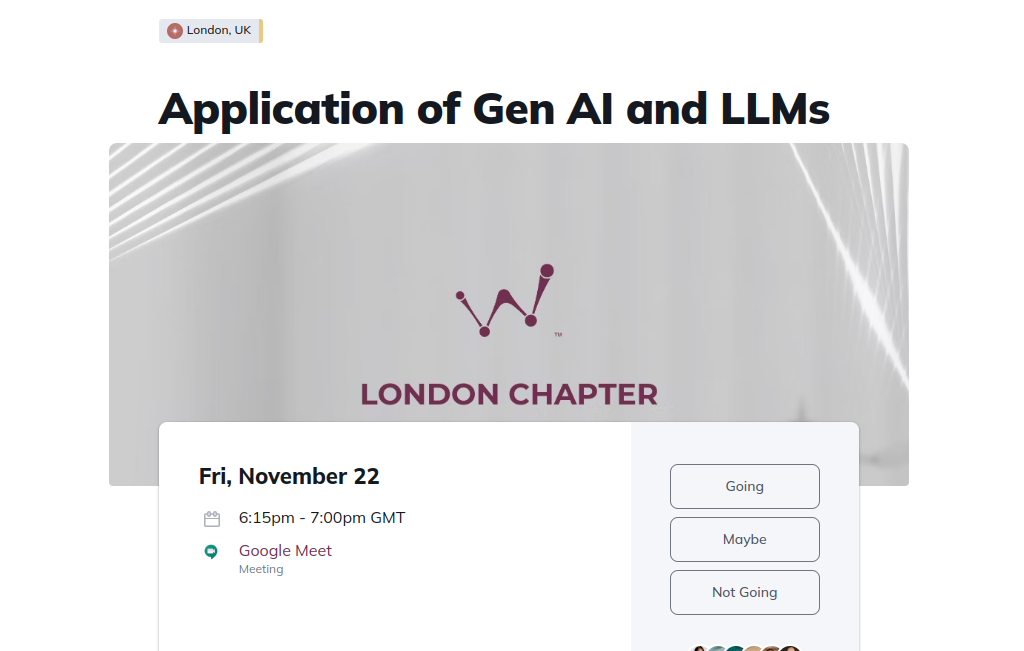
Harmony at Women In Data™️
Harmony at Women In Data™️ London Chapter (online event) On 22 November, we will present Harmony at Women In Data™️ London Chapter’s event on Application of Generative AI and LLMs. Thomas Wood will demonstrate Harmony and how it uses Gen AI. The event will be livestreamed.
⏲️ 25 minutes talk + 10 minutes Q&A 📅 Date: November 22nd 2024, 6:15 pm 📝 RSVP See also our past events 22 November 2024: Harmony at Women In Data™️ London Chapter 30 October 2024: Onboarding webinar for DOXA AI competition 8 October 2024: Harmony: a free online tool using LLMs for research in psychology and social sciences at AI|DL London 11 and 12 September 2024: Harmony at MethodsCon Futures in Manchester 2 July 2024: Harmony: NLP and generative models for psychology research at Pydata London 3 June 2024: Harmony Hackathon at UCL 5 May 2024: Harmony: A global platform for harmonisation, translation and cooperation in mental health at Melbourne Children’s LifeCourse Initiative seminar series.
ai-in-researchevents
Harmony at AI|DL meetup
Tech Talk at the AI|DL AI Meetup (London) Artificial Intelligence and Deep Learning for Enterprise Thomas Wood presents the Harmony project at the 19th AI and Deep Learning for Enterprise meetup on 8 October 2024.
In case you missed the talk about Harmony on Tuesday at Civo Tech Junction with AI and Deep Learning for Enterprise sponsored by Daemon, you can now watch the recording of the live stream on AI|DL’s channel.
ai-in-research
Harmony in the spotlight: Sense about Science recognises need for responsible AI in research
How are research funders reacting to the AI governance vacuum? A recent article by Sense about Science, a leading independent charity that promotes the public interest in sound science and evidence, highlights the growing need for responsible AI governance in research.
The article, titled Research funders tackle AI governance vacuum with pragmatic guidance, discusses the alarming gap between the rapid development and adoption of AI tools, and the lack of clear frameworks for their safe and ethical use.
psychologyevents
Harmony at MethodsCon: Futures in Manchester
MethodsCon in Manchester We have attended MethodsCon: Futures in Manchester, run by the National Centre for Research Methods on 11 and 12 September 2024 to present Harmony, the NLP and AI tool we have been developing for researchers in social science, funded by Wellcome and the Economic and Social Research Council. The events took place at The Edwardian Manchester.
Methods Showcase – 11th September The first event was a workshop on 11 September:
Hello! How can I assist you today?
Signup to our newsletter
The latest news on data harmonisation project.
You can unsubscribe at any time by clicking the link in the footer of our emails. For information about our privacy practices, please visit our website. We use Mailchimp as our marketing platform. By clicking below to subscribe, you acknowledge that your information will be transferred to Mailchimp for processing. Learn more about Mailchimp's privacy practices.